BLOG
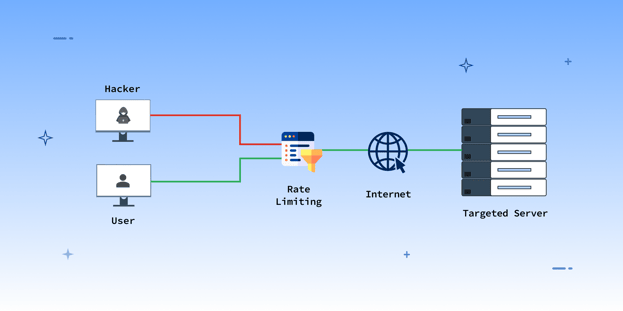
Learn how to protect your API from Denial of Service (DoS) attacks by putting rate limiting techniques in place.
BLOG
Hackers never rest. Neither should your security!
Stay ahead of emerging threats, vulnerabilities, and best practices in mobile app security—delivered straight to your inbox.
![]() Exclusive insights. Zero fluff. Absolute security.
Exclusive insights. Zero fluff. Absolute security.
![]() Join the Appknox Security Insider Newsletter!
Join the Appknox Security Insider Newsletter!

